Blockchain indexing with the help of APIs (called subgraphs) that make accessing data easier. The Graph’s is a noble pursuit and it’s generally known that they have done some remarkable work on this front with open networks, verifiable data integrity, robust security measures, and transparent governance.
Who?
Derek (Data Nexus)—Curator & Subgraph Developer
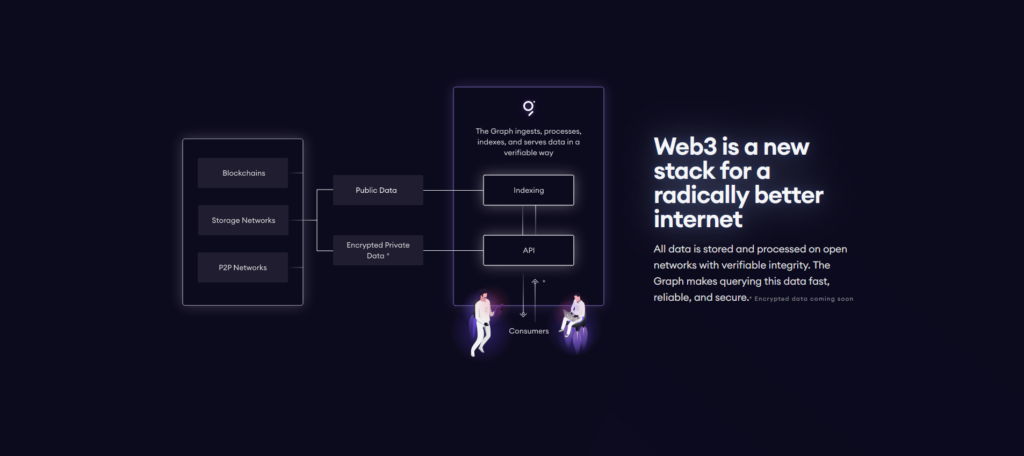
#1. Making blockchain data more accessible – what were the pain points or struggles that led to the development of The Graph? Also, what are the problems that The Graph’s many APIs solve?
Blockchains are built to be able to change data – which happens with each transaction. They were not optimized to be able to get rich data from the history. Consider wanting to know a basic piece of data such as “what is the Total Value Locked in a protocol?” Without a data indexing and aggregation system, this becomes too slow to satisfy a user. With the Graph, we update information as each block comes in so the computational work doesn’t need to repeat each time a user loads the page.
#2. Apart from querying data from Ethereum-based assets such as smart contracts & NFTs, what else can the “subgraphs” help us query in the future? Specifically, what asset classes and their metadata can they help us organize more neatly?
The Graph is already able to support 18 different blockchains and IPFS data. We are working to expose information that is off chain which will make it a decentralized & permissionless data hub for all knowledge.
#3. Which other blockchain ecosystems are you guys planning to expand to in the near future?
While many chains are supported by The Graph’s Hosted Service (centrally run by core developers), the decentralized mainnet is soon to support Gnosis and we will start indexing Polygon on our testnet next month.
#4. How hard is writing a subgraph? Let’s assume I wish to create one to index a specific asset class on a popular blockchain. What will be the basic steps? How will I tell the subgraph my parameters?
The syntax is built in Assembly Script, which is a strongly typed language. For those familiar with Type Script it will feel nearly identical. The Graph’s CLI will help build scaffolding for a contract you wish to listen to, and will prebuild your data structure so that all events are captured and listened to. From there you can start to build custom aggregations (and remove unnecessary events) to suit your use case.
#5. What are the security risks, if any, associated with open APIs and using them to query blockchain data?
When querying an open API from The Graph it is best practice to limit your API key to your owned domains and to your subgraph. That way, if a user is able to get the hands on your API Key, they cannot use it on their website for their subgraph.
Users committed to decentralizing their technology stack can in this way have peace of mind for the security of their billing wallet. Other consumers with their own centralized servers can wrap the API calls within it’s own API – this prevents the API key from being exposed.
#6. Is there any possibility that in the future, we would be able to compare and analyze datasets among wholly different asset classes and even networks using subgraphs?
This is already possible! Messari is building a subgraph schema standard for various network uses – think 1 query that works for many subgraphs across many chains.(insert Messari dashboard link)
#7. Is there any particular reason why deploying to a testnet isn’t supported? Will it ever be supported, given many developers might first want to test a subgraph with real users?
We do have a testnet available on Goerli, however the testnet GRT is valueless and thus indexers have no incentivization to start syncing this data. For the purpose of testing while in development, users can run a local instance of their subgraph or deploy to the studio which will index the information.
#8. The Graph has a very active and friendly community. Tell us about the current community and development strength, goals, and innovations.
The community has a common thread of decentralization woven into our individual fabrics. We tend to be builder focused which avoids a lot of noise that is typically found in the industry. For us it has been a complete joy to work with such an intelligent and caring community.
#9. Can you tell us how the current Graph economy works? More specifically, the workflow and interactions between the delegators and the indexer. How do delegators pick indexers?
There are two key roles and multiple helper roles within The Graphs economy. The key roles are a consumer (who requests data) and an indexer (who serves data). When data is requested by a consumer, they pay a micro fee for each query to the Indexer.
Indexers put up their own self-stake in GRT as a monetary trust guarantee that their will provide valid information – if an indexer provides malicious information they can be slashed. An indexers stake size helps determine how many subgraphs they can support and what their compensation will be for the labor provided to the network.
Delegation is a role that exists for token holders to empower specific indexers. When a delegator sees an indexer doing good work, they can stake their GRT to that indexer. The indexer is now able to earn more and shares a portion of their earnings with that delegator. Delegators stake is not subject to the same slashing as an indexer’s.
We recommend finding indexers who are active in the community (discord, forums, telegram channels etc.) and are actively serving queries (as can be seen in the query fees collected).
#10. Is there any system in place to ensure there’s no huge gap between cuts or APY offered, or more generally, to add some balance to the whole delegator-indexer paradigm? As a follow-up, how do you fight centralization within this paradigm?
Indexers are able to set their own cuts (the percentage of their commission). Additionally, rewards and query fees can vary depending on how intelligently an indexer manages their stake. So while two indexers may have the same cut percentages the most likely will have differing APY.
More importantly, it is easier to find higher reward opportunities when you are controlling a smaller amount of stake. So this acts as a natural power that can prevent stake centralization to a single indexer as delegators gravitate toward smaller indexers.
#11. Can someone write a subgraph that interacts with other subgraphs? If yes, what are the current use cases? If no, will it create any new opportunities for interoperable blockchains?
This is not currently available but it is a feature that has been requested many times and I suspect to see. When a protocol has a subgraph indexing data from multiple chains, currently they send one query to each of the respective subgraphs (and thus the data speed is reduced to the slowest of the batch). Ideally there will be a way to query all of the subgraphs with a single query. For now we have query composition tools such as The Graph Client library that can help facilitate this which has been a great solution in the meantime.
#12. Lastly, what are some innovations or features that you guys are working on currently?
The next major iteration that we expect to see is called Substreams. Right now data is ingested linearly (block 1 > block 2 > block 3 etc.). With substreams we are able to parallelize this activity to split the ingestion with multiple workers (worker 1 handles blocks 1 to 100, worker 2 handles blocks 101 to 200 etc.). A parallelized structure exponentially increases indexing speeds depending on the amount of workers the indexers applies.